Table of Contents
Gobblin JDBC writer & publisher
Gobblin is a general data ingestion framework that can extract, convert, and publish data. Currently publishing into JDBC compatible RDBMS is not in Gobblin and here we are introducing JDBC writer (and publisher) so that Gobblin can easily write into JDBC compatible RDBMS by using new JDBC writer at the same time reusing existing extraction, and conversion.
Proposed design
Requirements
- User can choose to replace the destination table.
- User can pass the staging table, for the case user does not have permission to create table. If user chose to use their own staging table, user can also choose to truncate the staging table.
- User should be able to skip staging table for performance reason.
- User can choose level of parallelism.
- For Avro → JDBC use case, user should be able to cherry pick the fields to be copied.
Design summary
- New JdbcWriter, JdbcPublisher will be introduced, along with AvroFieldsPickConverter and AvroToJdbcEntry.
- Figure 1 shows Gobblin general flow and figure 2 shows the specific flow; Avro → RDBMS through JDBC.
- JdbcWriter will use staging table mainly for failure handling. Since Gobblin breaks down the job into multiple task and process it in parallel, each writer will hold transaction and there will be more than one transaction against the database. If there’s no staging table and writer writes directly to destination table, partial failure among the writers may result partial data push into destination table. Having partial data is mostly bad for consumption and could also result subsequent failure of next data load due to data inconsistency. Also, having partial data also makes it hard to retry on failure. Thus, Gobblin will use staging table so that writer writes into staging table and publisher can copy data from staging table into destination table in one single transaction. Having one transaction from the publisher level enables Gobblin to revert back to original on failure and make it able to be retried from previous state.
- For performance reason, and from the requirement, user may skip staging. This comes with the cost of giving up failure handling and for this case Gobblin does not guarantee recovery from failure. Will introduce WriterInitializer for the case that writer needs an initialization but needs to be done before going on parallel processing. (more on below)
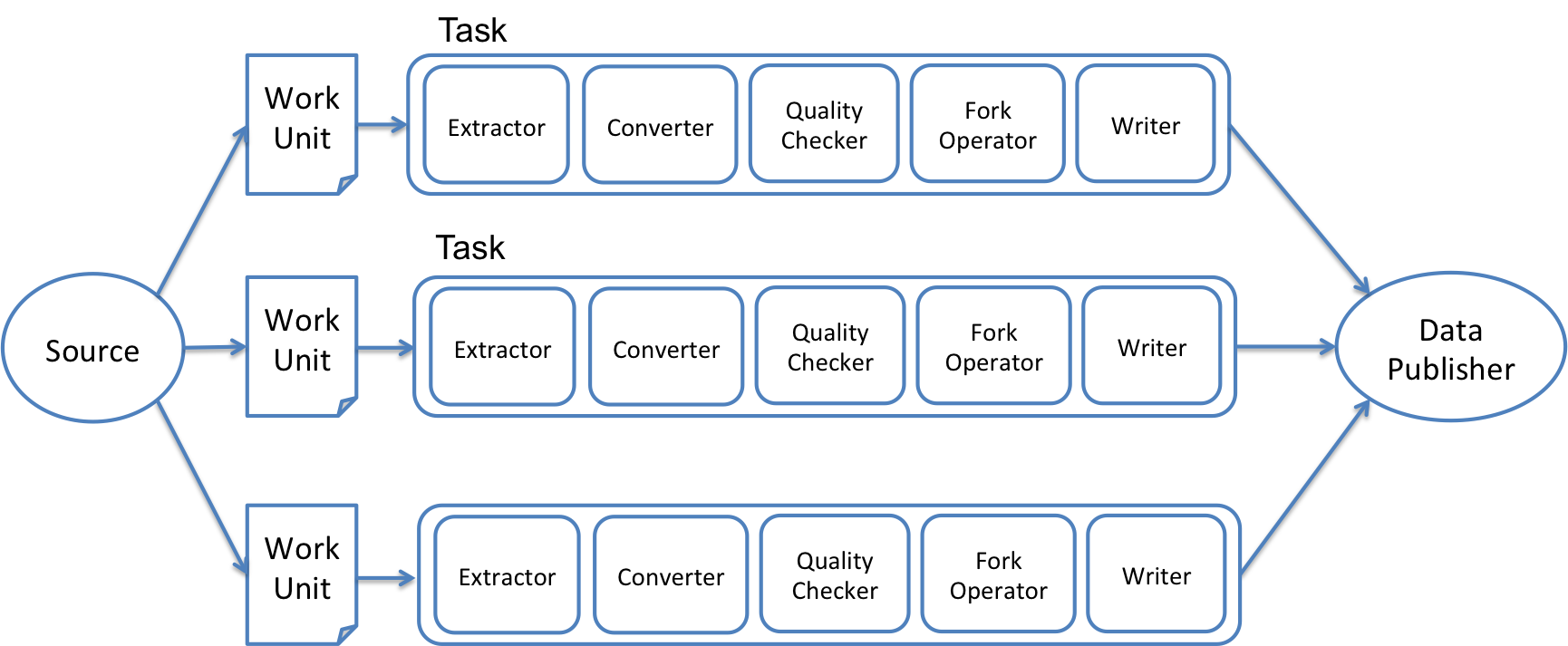
- figure 1. Gobblin general flow -

- figure 2. Gobblin Avro → RDBMS through JDBC specific flow -
- AvroFieldsPickConverter will cherry pick the columns that user wants.
- AvroToJdbcEntryConverter will convert Avro to JDBC entry.
- JdbcWriter will write JdbcEntry to staging table. (user can skip staging which is addressed below in JDBC Writer/Publisher section).
- JdbcPublisher will write into destination table.
Design detail
WriterInitializer
Note that this is a new interface where its responsibility is to initialize writer, which means it’s tied to writer’s implementation, and clean what it initialized.
Reasons of introducing writer initializer:
-
The main reason for this initializer is to perform initialization but not in parallel environment. As writer subjects to run in parallel, certain task that needs to be done only once across all writers is hard to be done. For example, if user chose to skip staging table and also chose to replace destination table, the initialization task would be truncating destination table which needs to be done only once before all writers start writing. This is simply hard to be done in parallel environment and better to avoid trying it for simplicity.
-
Another reason for writer initializer is to simplify the cleanup process. As writer initializer initializes things, it also knows what to clean up. Instead of having other code to figure out what to clean up on which branch and condition all over again, closing writer initializer at the end of the job will just simply clean it up.(This pattern is widely used in JDK(e.g: Stream), where many classes implements interface Closeable). This clean up can be done in writer, but writer is currently being closed in task level, where there’s a case that rest of the flow still needs it. (e.g: staging table should not be cleaned until publish is completed.)
-
Currently, Gobblin has a logic to clean up the the staging data in JobLauncherUtils which is specific to FsDataWriter, where AbstractJobLauncher has the logic to figure out what kind of clean up method of JobLauncherUtils needs to be called. Ideally, we will hide this implementation of clean up behind the interface of WriterInitializer.
-
Figure 3 shows interface of WriterInitializer. WriterInitializer will be extensible in Gobblin via factory method pattern where any writer can plugin their initialization code if needed.
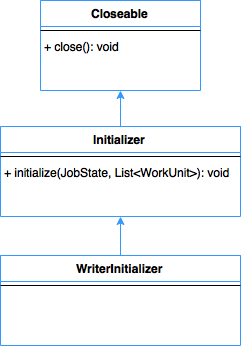
- figure 3. Class diagram for WriterInitializer interface -
JdbcWriterInitializer
- JdbcWriterInitializer will be the first class implements WriterInitializer interface. This will be instantiated by AbstractJobLauncher after Source creates WorkUnit and always get closed by AbstractJobLauncher when job is finished regardless fail or success.
- By default, JdbcWriterInitializer will create staging tables based on the structure of the target table. Therefore it's necessary to create the target table first. Staging tables are created per Workunit, in which there can be more than one staging table. Having multiple staging table will make parallelism easier for publisher when moving data from staging table to destination. Any table created by JdbcWriterInitializer will be remembered and later will be dropped when it’s being closed.
- Staging will be placed in same destination host, same database, some temporary table name, with same structure. The main purpose of staging table for handling failure. Without staging table, it is hard to recover from failure, because writers writes into table in multiple transactions. Additionally, staging table also brings data integrity check before publishing into destination.
- Before creating the staging table, JdbcWriterInitializer will validate if user has drop table privilege to make sure it can drop it later on.
- User can choose to use their own staging table. This is to support the use case when user does not have privilege to create table. When user chooses to use their own staging table, JdbcWriterInitializer will truncate the table later when it’s being closed.
- Staging table initially should be always empty. User who chose to use user’s own staging table can also choose to truncate staging table. If staging table is not empty and user does not choose to truncate table, JdbcWriterInitializer will make the job fail.
- If user chose to skip staging table and replace the output, JdbcWriterInitializer will truncate destination table. This is because destination table needs to be emptied prior going into parallel processing as more than one writer will start writing simultaneously.
- Figure 4 shows overall flow of JdbcWriterInitializer.
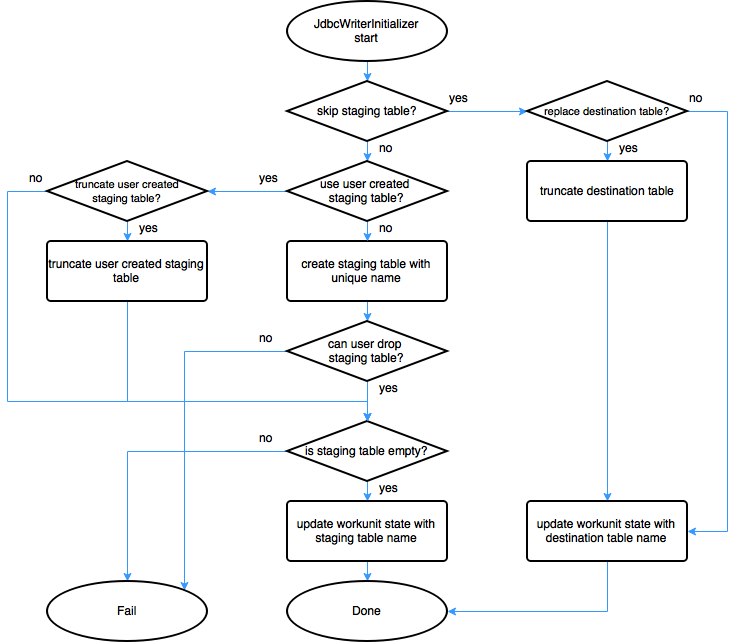
- figure 4. JdbcWriterInitializer flow -
AvroFieldsPickConverter
- User can define which fields to be copied. Given input from the user, it will narrow down the number of columns by updating schema and data.
AvroToJdbcEntryConverter
- Will convert avro schema and data into JdbcEntrySchema and JdbcEntryData. JdbcEntrySchema consists of pairs of column name and JDBCTypes, and JdbcEntry consists of pairs of column names and object where object can be directly used against PreparedStatement.setObject().
- Although Avro schema can be a recursive structure by having record in the record, RDBMS table structure is not a recursive data structure. Thus, AvroToJdbcEntryConverter does not accept Avro schema that has record type inside record type.
- Both JdbcEntrySchema and JdbcEntry will be case sensitive because Avro field name is case sensitive, and many widely used RDBMS are case sensitive on column name as well.
- In case there’s a mismatch on column names, AvroToJdbcEntryConverter will take column name mapping between Avro field name and Jdbc column name.
JdbcWriter
- Uses JDBC to persist data into staging table in task level.
- By default it will persist into staging area (and will be put into final destination by publisher).
- Staging table is already ready by WriterInitializer.
- Input column names should exactly match Jdbc column names. User can convert the name using AvroToJdbcEntryConverter.
- Schema evolution: The number of input columns is expected to be equal or smaller than the number of columns in Jdbc. This is to prevent unintended outcome from schema evolution such as additional column. As underlying Jdbc RDBMS can declare constraints on its schema, writer will allow if number of columns in Jdbc is greater than number of input columns.
- number of input columns <= number of columns in Jdbc
- Each writer will open one transaction. Having one transaction per writer has its tradeoffs:
- Pro: Simple on failure handling as you can just simply execute rollback on failure. Basically, it will revert back to previous state so that the job can retry the task.
- Con: It can lead up to long lived transaction and it can face scalability issue. (Not enough disk space for transaction log, number of record limit on one transaction (2.1B for Postgre sql), etc)
- JdbcWriter will go with one transaction per writer for it’s simplicity on failure handling. Scalability issue with long transaction can be overcome by increasing partition which makes transaction short.
- During the design meeting, we’ve discussed that long transaction could be a problem. One suggestion came out during the meeting was commit periodically. This will address long transaction problem, but we also discussed it would be hard on failure handling. Currently, Gobblin does task level retry on failure and there were three options we’ve discussed. (There was no silver bullet solution from the meeting.) Note that these are all with committing periodically.
- Revert to previous state: For writer, this will be delete the record it wrote. For JdbcWriter, it could use it’s own staging table or could share staging table with other writer. As staging table can be passed by user where we don’t have control of, not able to add partition information, it is hard to revert back to previous state for all cases.
- Ignore duplicate: The idea is to use Upsert to perform insert or update. As it needs to check the current existence in the dataset, it is expected to show performance degradation. Also, possibility of duplicate entry was also discussed.
- Water mark: In order to use water mark in task level, writer needs to send same order when retried which is not guaranteed.
- Data with over 200M record was tested with single transaction and it had no problem in MySQL 5.6.
- Operation:
- Write operation will write into staging table. (If user chose to skip staging table, write operation will write into destination table directly.)
- Commit operation will commit the transaction.
- Close operation will close database connection. If there was a failure, it will execute rollback before closing connection.
Skipping staging table
- From the requirement, user can choose to skip staging for performance reason. In this case, writer will directly persist into final destination. Without staging table, it is hard to recover from failure as mentioned above and for this reason, if user does not want staging, the framework does not guarantee any recovery from the failure.
- If user configures "job.commit.policy=partial" and "publish.at.job.level=false", this means it won't be published in job level and it allows partial success commit. This will make Gobblin to skip staging table as it aligns with the behavior of skipping staging. The reason to reuse these two parameters instead of introducing new parameter is to avoid parameters contradicting each other.
- Figure 4 shows overall flow of JDBC writer.
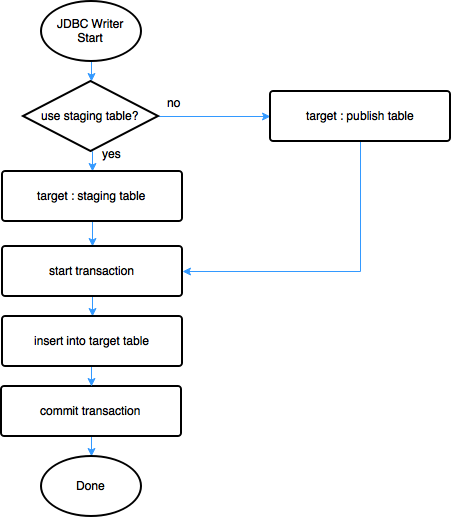
- figure 5. JDBC Writer flow -
JDBC Publisher
- Uses JDBC to publish final result into output.
- If user chose to not to use staging table, for performance reason, JDBC publisher won't do anything as the output is already updated by the writer(s). More precisely, the parameter makes Gobblin skip staging table, will make publisher to be skipped.
- JDBC publisher will copy data from staging table via SQL command that underlying database provides. (Renaming staging table is not viable mainly because 1. it's hard to copy exact structure as original one (constraints, index, sequence, foreign keys, etc). 2. couple of underlying database system, rename requires no active connection to the table.)
- A publisher will open one transaction. Being processed in single transaction, any failure can be reverted by rolling back transaction.
Operation:
- PublishData operation opens single transaction and writes into destination table from staging table. If there is any error, transaction will be rolled back. Once completed successfully, transaction will be committed.
- Parallelism: Currently parallelism in publisher level is not supported. For example the MySQL Writer fails on deleting all from table before inserting new data using global transaction with multiple connections.
- PublishMeta won’t do anything.
- Figure 6 shows overall flow of JDBC publisher.
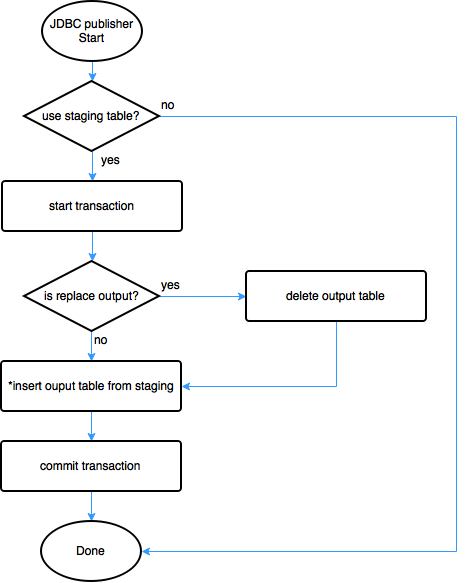
- figure 6. Gobblin_JDBC_Publisher -
Concrete implementations
To configure a concrete writer, please refer the JDBC Writer Properties section in the Configuration Glossary.
MySQL Writer
The MySQL writer uses buffered inserts to increase performance.
The sink configuration for MySQL in a Gobblin job is as follows:
writer.destination.type=MYSQL
writer.builder.class=org.apache.gobblin.writer.JdbcWriterBuilder
data.publisher.type=org.apache.gobblin.publisher.JdbcPublisher
jdbc.publisher.url=jdbc:mysql://host:3306
jdbc.publisher.driver=com.mysql.jdbc.Driver
converter.classes=org.apache.gobblin.converter.jdbc.AvroToJdbcEntryConverter
# If field name mapping is needed between the input Avro and the target table:
converter.avro.jdbc.entry_fields_pairs={\"src_fn\":\"firstname\",\"src_ln\":\"lastname\"}
Teradata Writer
Similarly to the MySQL Writer, this writer also inserts data in batches, configured by writer.jdbc.batch_size.
Ideally, for performance reasons the target table is advised to be set to type MULTISET, without a primary index.
Please note, that the Teradata JDBC drivers are not part of Gobblin, one needs to obtain them from
Teradata and pass them as job specific jars to the
Gobblin submitter scripts. Teradata may use the FASTLOAD option during the insert if conditions are met.
The sink configuration for Teradata in a Gobblin job is as follows:
writer.destination.type=TERADATA
writer.builder.class=org.apache.gobblin.writer.JdbcWriterBuilder
data.publisher.type=org.apache.gobblin.publisher.JdbcPublisher
jdbc.publisher.url=jdbc:teradata://host/TMODE=ANSI,CHARSET=UTF16,TYPE=FASTLOAD
jdbc.publisher.driver=com.teradata.jdbc.TeraDriver
converter.classes=org.apache.gobblin.converter.jdbc.AvroToJdbcEntryConverter
# If field name mapping is needed between the input Avro and the target table:
converter.avro.jdbc.entry_fields_pairs={\"src_fn\":\"firstname\",\"src_ln\":\"lastname\"}
Performance and Scalability
As Gobblin can dial up parallelism, the bottleneck of performance will be the underlying RDBMS. Thus, performance and scalability will be mainly up to underlying RDBMS.
Benchmark:
MySQL Writer performance test on 80k records. Each entry consists of 14 fields with sparse density.
Few observations:
- Starting from batch insert size 1,000, the performance gain diminishes.
- The parallelism does not show much of gain. This is mostly because of the overhead of parallelism. Parallelism is expected to show more performance gain on bigger record sets.
| Batch insert size | Parallelism | Elapsed |
|---|---|---|
| 10 | 1 | 17 minutes |
| 30 | 1 | 5 minutes 30 seconds |
| 100 | 1 | 2 minutes 17 seconds |
| 1,000 | 1 | 40 seconds |
| 10,000 | 1 | 43 seconds |
| 1,000 | 2 | 42 seconds |
| 1,000 | 4 | 44 seconds |
| 1,000 | 8 | 57 seconds |
All tests used:
- Hadoop 2.3 in Pseudo-distributed mode on CPU: 12 cores @1.2GHz, Memory: 64GBytes
- MySQL server 5.6.21 with InnoDB storage engine, and compression on. Server runs on Dual CPU Intel Xeon 6 cores @2.5GHz, Memory: 48 GBytes, and HDD: 2.4TB (10K RPM)
Important note
- As Gobblin framework comes with parallel processing via Hadoop, it can easily overburden the underlying RDBMS. User needs to choose parallelism level conservativley.