Table of Contents
Gobblin Architecture Overview
Gobblin is built around the idea of extensibility, i.e., it should be easy for users to add new adapters or extend existing adapters to work with new sources and start extracting data from the new sources in any deployment settings. The architecture of Gobblin reflects this idea, as shown in Fig. 1 below:
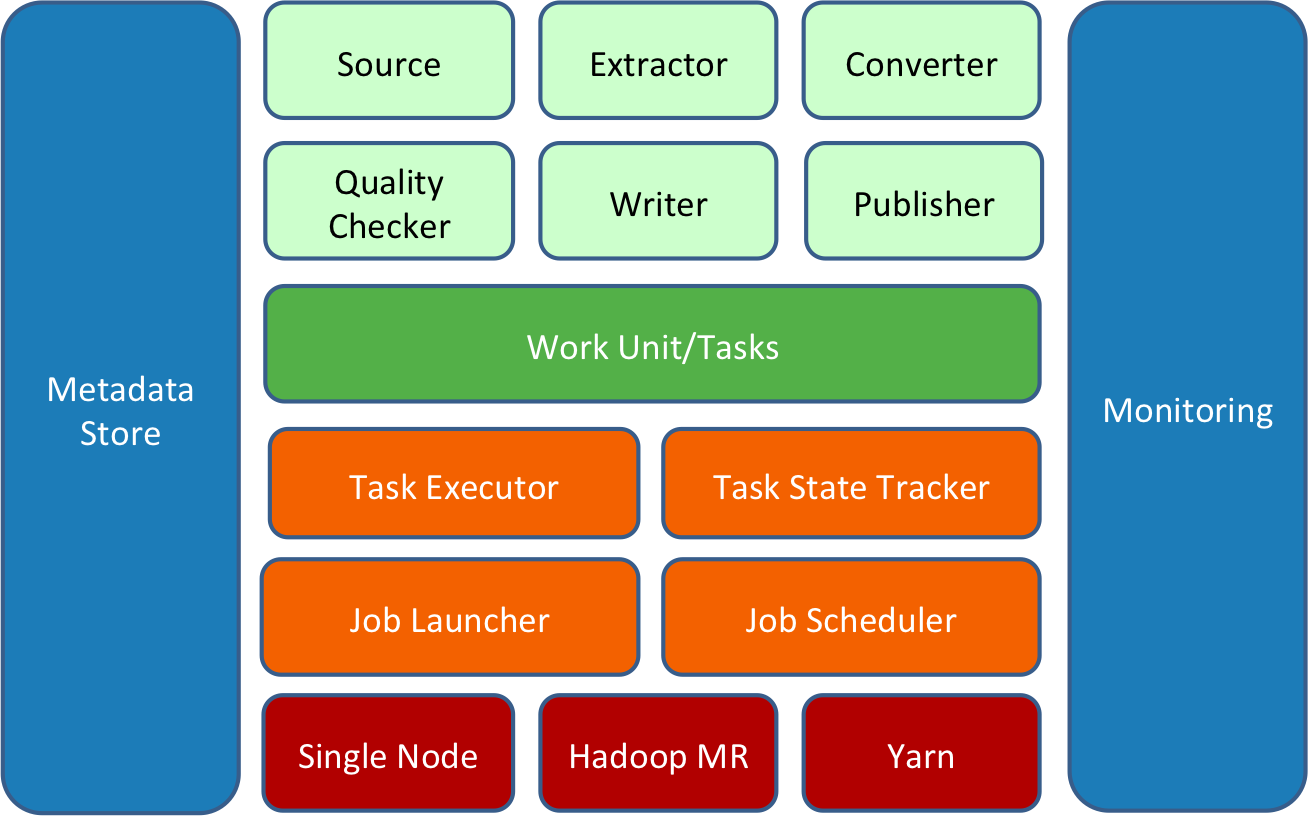
Figure 1: Gobblin Architecture Overview
A Gobblin job is built on a set of constructs (illustrated by the light green boxes in the diagram above) that work together in a certain way and get the data extraction work done. All the constructs are pluggable through the job configuration and extensible by adding new or extending existing implementations. The constructs will be discussed in Gobblin Constructs.
A Gobblin job consists of a set of tasks, each of which corresponds to a unit of work to be done and is responsible for extracting a portion of the data. The tasks of a Gobblin job are executed by the Gobblin runtime (illustrated by the orange boxes in the diagram above) on the deployment setting of choice (illustrated by the red boxes in the diagram above).
The Gobblin runtime is responsible for running user-defined Gobblin jobs on the deployment setting of choice. It handles the common tasks including job and task scheduling, error handling and task retries, resource negotiation and management, state management, data quality checking, data publishing, etc.
Gobblin currently supports two deployment modes: the standalone mode on a single node and the Hadoop MapReduce mode on a Hadoop cluster. We are also working on adding support for deploying and running Gobblin as a native application on YARN. Details on deployment of Gobblin can be found in Gobblin Deployment.
The running and operation of Gobblin are supported by a few components and utilities (illustrated by the blue boxes in the diagram above) that handle important things such as metadata management, state management, metric collection and reporting, and monitoring.
Gobblin Job Flow
A Gobblin job is responsible for extracting data in a defined scope/range from a data source and writing data to a sink such as HDFS. It manages the entire lifecycle of data ingestion in a certain flow as illustrated by Fig. 2 below.
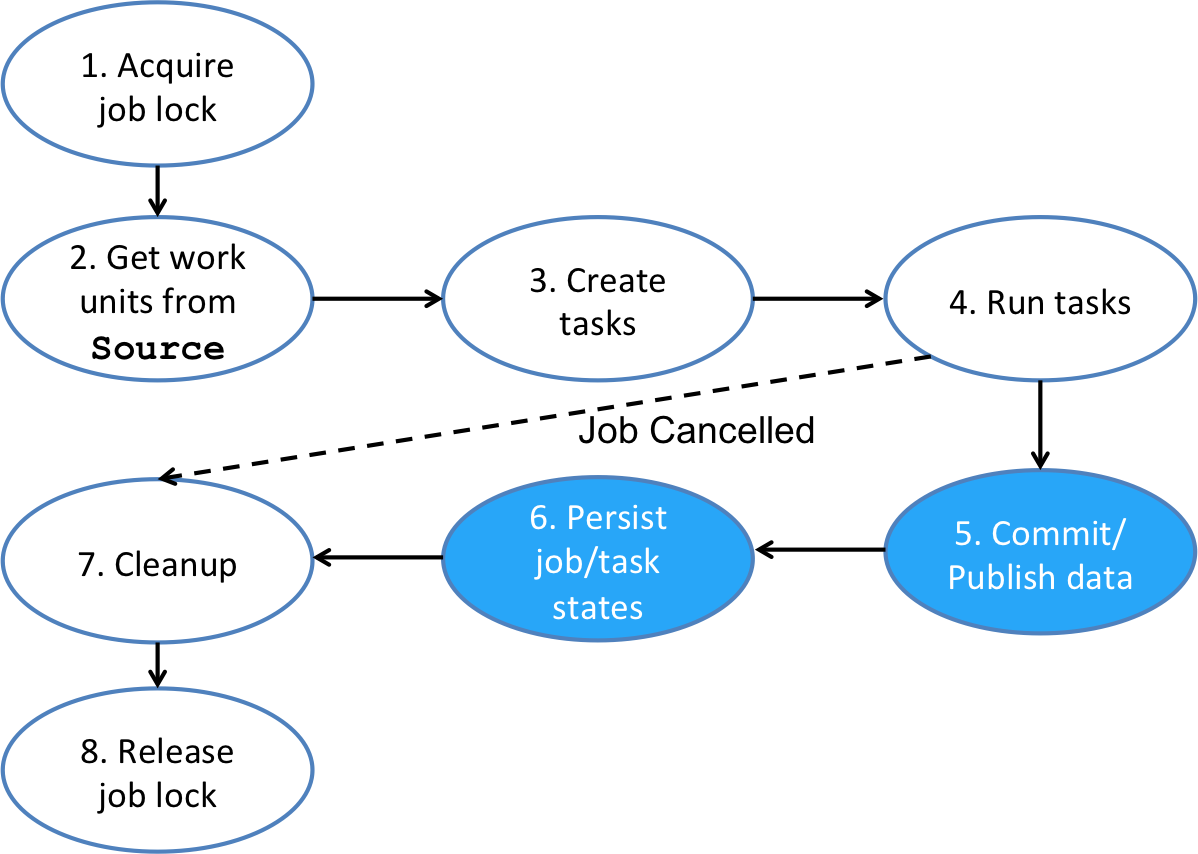
Figure 2: Gobblin Job Flow
-
A Gobblin job starts with an optional phase of acquiring a job lock. The purpose of doing this is to prevent the next scheduled run of the same job from starting until the current run finishes. This phase is optional because some job schedulers such as Azkaban is already doing this.
-
The next thing the job does is to create an instance of the
Sourceclass specified in the job configuration. ASourceis responsible for partitioning the data ingestion work into a set ofWorkUnits, each of which represents a logic unit of work for extracting a portion of the data from a data source. ASourceis also responsible for creating aExtractorfor eachWorkUnit. AExtractor, as the name suggests, actually talks to the data source and extracts data from it. The reason for this design is that Gobblin'sSourceis modeled after Hadoop'sInputFormat, which is responsible for partitioning the input intoSplits as well as creating aRecordReaderfor eachSplit. -
From the set of
WorkUnits given by theSource, the job creates a set of tasks. A task is a runtime counterpart of aWorkUnit, which represents a logic unit of work. Normally, a task is created perWorkUnit. However, there is a special type ofWorkUnits calledMultiWorkUnitthat wraps multipleWorkUnits for which multiple tasks may be created, one per wrappedWorkUnit. -
The next phase is to launch and run the tasks. How tasks are executed and where they run depend on the deployment setting. In the standalone mode on a single node, tasks are running in a thread pool dedicated to that job, the size of which is configurable on a per-job basis. In the Hadoop MapReduce mode on a Hadoop cluster, tasks are running in the mappers (used purely as containers to run tasks).
-
After all tasks of the job finish (either successfully or unsuccessfully), the job publishes the data if it is OK to do so. Whether extracted data should be published is determined by the task states and the
JobCommitPolicyused (configurable). More specifically, extracted data should be published if and only if any one of the following two conditions holds: -
JobCommitPolicy.COMMIT_ON_PARTIAL_SUCCESSis specified in the job configuration. -
JobCommitPolicy.COMMIT_ON_FULL_SUCCESSis specified in the job configuration and all tasks were successful. -
After the data extracted is published, the job persists the job/task states into the state store. When the next scheduled run of the job starts, it will load the job/task states of the previous run to get things like watermarks so it knows where to start.
-
During its execution, the job may create some temporary working data that is no longer needed after the job is done. So the job will cleanup such temporary work data before exiting.
-
Finally, an optional phase of the job is to release the job lock if it is acquired at the beginning. This gives green light to the next scheduled run of the same job to proceed.
If a Gobblin job is cancelled before it finishes, the job will not persist any job/task state nor commit and publish any data (as the dotted line shows in the diagram).
Gobblin Constructs
As described above, a Gobblin job creates and runs tasks, each of which is responsible for extracting a portion of the data to be pulled by the job. A Gobblin task is created from a WorkUnit that represents a unit of work and serves as a container of job configuration at runtime. A task composes the Gobblin constructs into a flow to extract, transform, checks data quality on, and finally writes each extracted data record to the specified sink. Fig. 3 below gives an overview on the Gobblin constructs that constitute the task flows in a Gobblin job.
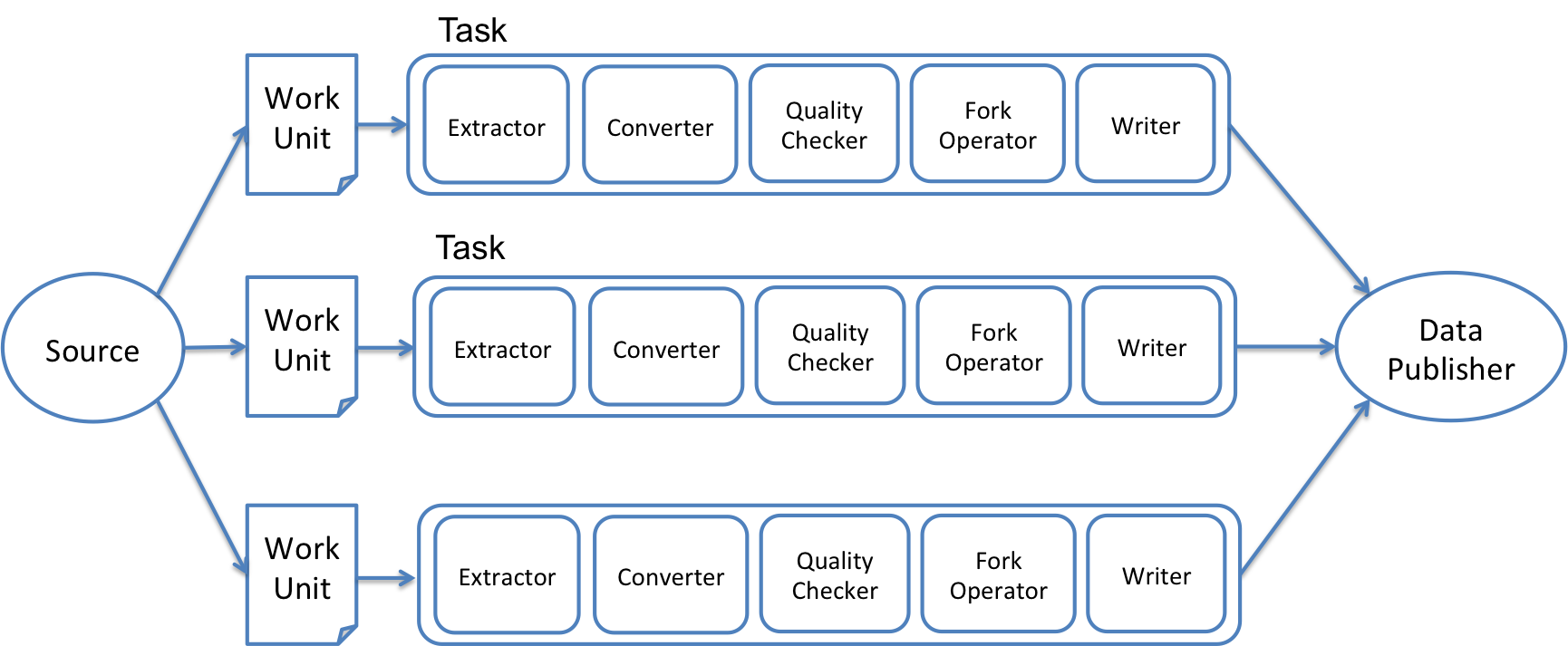
Figure 3: Gobblin Constructs
Source and Extractor
A Source represents an adapter between a data source and Gobblin and is used by a Gobblin job at the beginning of the job flow. A Source is responsible for partitioning the data ingestion work into a set of WorkUnits, each of which represents a logic unit of work for extracting a portion of the data from a data source.
A Source is also responsible for creating an Extractor for each WorkUnit. An Extractor, as the name suggests, actually talks to the data source and extracts data from it. The reason for this design is that Gobblin's Source is modeled after Hadoop's InputFormat, which is responsible for partitioning the input into Splits as well as creating a RecordReader for each Split.
Gobblin out-of-the-box provides some built-in Source and Extractor implementations that work with various types of of data sources, e.g., web services offering some Rest APIs, databases supporting JDBC, FTP/SFTP servers, etc. Currently, Extractors are record-oriented, i.e., an Extractor reads one data record at a time, although internally it may choose to pull and cache a batch of data records. We are planning to add options for Extractors to support byte-oriented and file-oriented processing.
Converter
A Converter is responsible for converting both schema and data records and is the core construct for data transformation. Converters are composible and can be chained together as long as each adjacent pair of Converters are compatible in the input and output schema and data record types. This allows building complex data transformation from simple Converters. Note that a Converter converts an input schema to one output schema. It may, however, convert an input data record to zero (1:0 mapping), one (1:1 mapping), or many (1:N mapping) output data records. Each Converter converts every output records of the previous Converter, except for the first one that converts the original extracted data record. When converting a data record, a Converter also takes in the output converted schema of itself, except for the first one that takes in the original input schema. So each converter first converts the input schema and then uses the output schema in the conversion of each data record. The output schema of each converter is fed into both the converter itself for data record conversion and also the next converter. Fig. 4 explains how Converter chaining works using three example converters that have 1:1, 1:N, and 1:1 mappings for data record conversion, respectively.
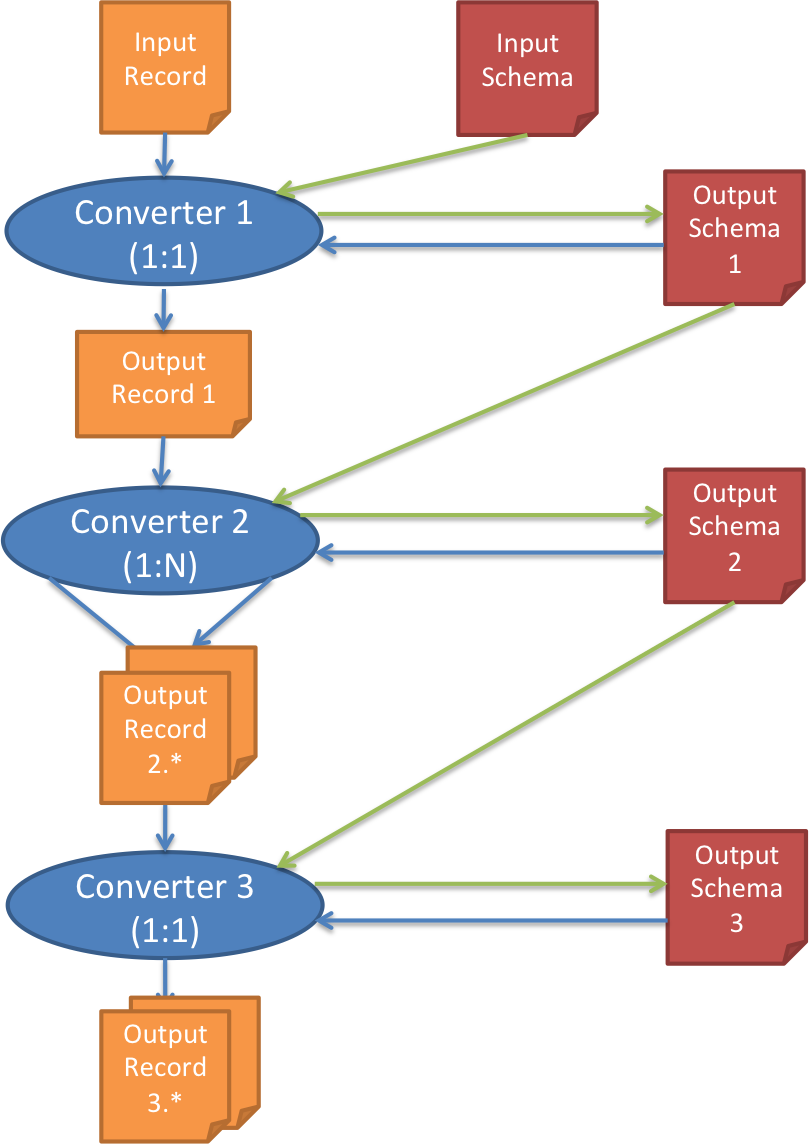
Figure 4: How Converter Chaining Works
Quality Checker
A QualityChecker, as the name suggests, is responsible for data quality checking. There are two types of QualityCheckers: one that checks individual data records and decides if each record should proceed to the next phase in the task flow and the other one that checks the entire task output and decides if data can be committed. We call the two types row-level QualityCheckers and task-level QualityCheckers, respectively. A QualityChecker can be MANDATORY or OPTIONAL and will participate in the decision on if quality checking passes if and only if it is MANDATORY. OPTIONAL QualityCheckers are informational only. Similarly to Converters, more than one QualityChecker can be specified and in this case, quality checking passes if and only if all MANDATORY QualityCheckers give a PASS.
Fork Operator
A ForkOperator is a type of control operators that allow a task flow to branch into multiple streams, each of which goes to a separately configured sink. This is useful for situations, e.g., that data records need to be written into multiple different storages, or that data records need to be written out to the same storage (say, HDFS) but in different forms for different downstream consumers.
Data Writer
A DataWriter is responsible for writing data records to the sink it is associated to. Gobblin out-of-the-box provides an AvroHdfsDataWriter for writing data in Avro format onto HDFS. Users can plugin their own DataWriters by specifying a DataWriterBuilder class in the job configuration that Gobblin uses to build DataWriters.
Data Publisher
A DataPublisher is responsible for publishing extracted data of a Gobblin job. Gobblin ships with a default DataPublisher that works with file-based DataWriters such as the AvroHdfsDataWriter and moves data from the output directory of each task to a final job output directory.
Gobblin Task Flow
Fig. 5 below zooms in further and shows the details on how different constructs are connected and composed to form a task flow. The same task flow is employed regardless of the deployment setting and where tasks are running.
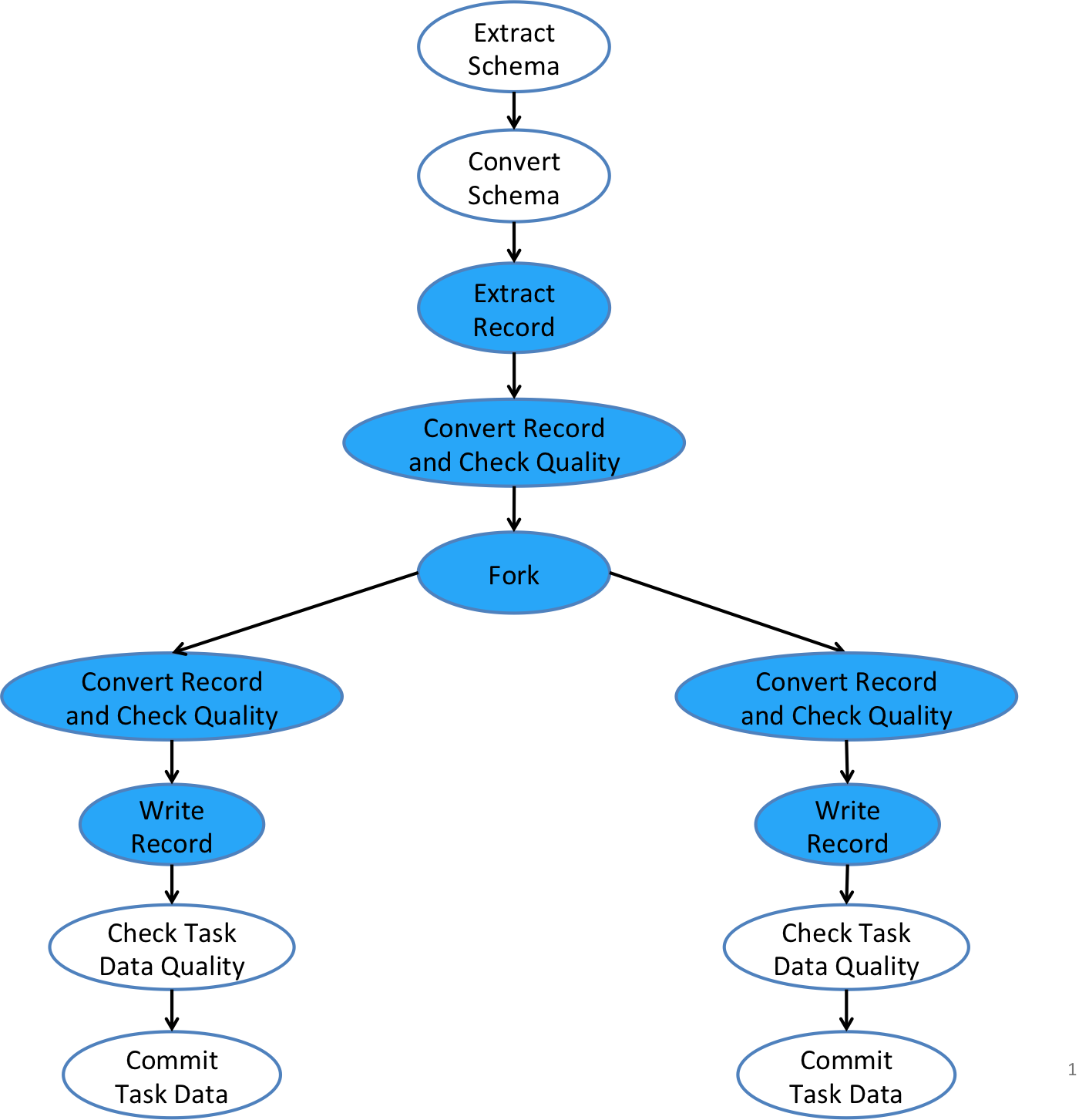
Figure 5: Gobblin Task Flow
A Gobblin task flow consists of a main branch and a number of forked branches coming out of a ForkOperator. It is optional to specify a ForkOperator in the job configuration. When no ForkOperator is specified in the job configuration, a Gobblin task flow uses a IdentityForkOperator by default with a single forked branch. The IdentityForkOperator simply connects the master branch and the single forked branch and passes schema and data records between them. The reason behind this is it avoids special logic from being introduced into the task flow when a ForkOperator is indeed specified in the job configuration.
The master branch of a Gobblin task starts with schema extraction from the source. The extracted schema will go through a schema transformation phase if at least one Converter class is specified in the job configuration. The next phase is to repeatedly extract data records one at a time. Each extracted data record will also go through a transformation phase if at least one Converter class is specified. Each extracted (or converted if applicable) data record is fed into an optional list of row-level QualityCheckers.
Data records that pass the row-level QualityCheckers will go through the ForkOperator and be further processed in the forked branches. The ForkOperator allows users to specify if the input schema or data record should go to a specific forked branch. If the input schema is specified not to go into a particular branch, that branch will be ignored. If the input schema or data record is specified to go into more than one forked branch, Gobblin assumes that the schema or data record class implements the Copyable interface and will attempt to make a copy before passing it to each forked branch. So it is very important to make sure the input schema or data record to the ForkOperator is an instance of Copyable if it is going into more than one branch.
Similarly to the master branch, a forked branch also processes the input schema and each input data record (one at a time) through an optional transformation phase and a row-level quality checking phase. Data records that pass the branch's row-level QualityCheckers will be written out to a sink by a DataWriter. Each forked branch has its own sink configuration and a separate DataWriter.
Upon successful processing of the last record, a forked branch applies an optional list of task-level QualityCheckers to the data processed by the branch in its entirety. If this quality checking passes, the branch commits the data and exits.
A task flow completes its execution once every forked branches commit and exit. During the execution of a task, a TaskStateTracker keeps track of the task's state and a core set of task metrics, e.g., total records extracted, records extracted per second, total bytes extracted, bytes extracted per second, etc.
Job State Management
Typically a Gobblin job runs periodically on some schedule and each run of the job is extracting data incrementally, i.e., extracting new data or changes to existing data within a specific range since the last run of the job. To make incremental extraction possible, Gobblin must persist the state of the job upon the completion of each run and load the state of the previous run so the next run knows where to start extracting. Gobblin maintains a state store that is responsible for job state persistence. Each run of a Gobblin job reads the state store for the state of the previous run and writes the state of itself to the state store upon its completion. The state of a run of a Gobblin job consists of the job configuration and any properties set at runtime at the job or task level.
Out-of-the-box, Gobblin uses an implementation of the state store that serializes job and task states into Hadoop SequenceFiles, one per job run. Each job has a separate directory where its job and task state SequenceFiles are stored. The file system on which the SequenceFile-based state store resides is configurable.
Handling of Failures
As a fault tolerance data ingestion framework, Gobblin employs multiple level of defenses against job and task failures. For job failures, Gobblin keeps track of the number of times a job fails consecutively and optionally sends out an alert email if the number exceeds a defined threshold so the owner of the job can jump in and investigate the failures. For task failures, Gobblin retries failed tasks in a job run up to a configurable maximum number of times. In addition to that, Gobblin also provides an option to enable retries of WorkUnits corresponding to failed tasks across job runs. The idea is that if a task fails after all retries fail, the WorkUnit based on which the task gets created will be automatically included in the next run of the job if this type of retries is enabled. This type of retries is very useful in handling intermittent failures such as those due to temporary data source outrage.
Job Scheduling
Like mentioned above, a Gobblin job typically runs periodically on some schedule. Gobblin can be integrated with job schedulers such as Azkaban,Oozie, or Crontab. Out-of-the-box, Gobblin also ships with a built-in job scheduler backed by a Quartz scheduler, which is used as the default job scheduler in the standalone deployment and it supports cron-based triggers using the configuration property job.schedule for defining the cron schedule. An important feature of Gobblin is that it decouples the job scheduler and the jobs scheduled by the scheduler such that different jobs may run in different deployment settings. This is achieved using the abstraction JobLauncher that has different implementations for different deployment settings. For example, a job scheduler may have 5 jobs scheduled: 2 of them run locally on the same host as the scheduler using the LocalJobLauncher, whereas the rest 3 run on a Hadoop cluster somewhere using the MRJobLauncher. Which JobLauncher to use can be simply configured using the property launcher.type. Please refer to this tutorial for more information on how to use and configure a cron-based trigger.