Table of Contents
Introduction
Gobblin currently is capable of running in the standalone mode on a single machine or in the MapReduce (MR) mode as a MR job on a Hadoop cluster. A Gobblin job is typically running on a schedule through a scheduler, e.g., the built-in JobScheduler, Azkaban, or Oozie, and each job run ingests new data or data updated since the last run. So this is essentially a batch model for data ingestion and how soon new data becomes available on Hadoop depends on the schedule of the job.
On another aspect, for high data volume data sources such as Kafka, Gobblin typically runs in the MR mode with a considerable number of tasks running in the mappers of a MR job. This helps Gobblin to scale out for data sources with large volumes of data. The MR mode, however, suffers from problems such as large overhead mostly due to the overhead of submitting and launching a MR job and poor cluster resource usage. The MR mode is also fundamentally not appropriate for real-time data ingestion given its batch nature. These deficiencies are summarized in more details below:
- In the MR mode, every Gobblin job run starts a new MR job, which costs a considerable amount of time to allocate and start the containers for running the mapper/reducer tasks. This cost can be totally eliminated if the containers are already up and running.
- Each Gobblin job running in the MR mode requests a new set of containers and releases them upon job completion. So it's impossible for two jobs to share the containers even though the containers are perfectly capable of running tasks of both jobs.
- In the MR mode, All
WorkUnits are pre-assigned to the mappers before launching the MR job. The assignment is fixed by evenly distributing theWorkUnits to the mappers so each mapper gets a fair share of the work in terms of the number ofWorkUnits. However, an evenly distributed number ofWorkUnits per mapper does not always guarantee a fair share of the work in terms of the volume of data to pull. This, combined with the fact that the mappers that finish earlier cannot "steal"WorkUnits assigned to other mappers, means the responsibility of load balancing is on theSourceimplementations, which is not trivial to do, and is virtually impossible in heterogeneous Hadoop clusters where different nodes have different capacity. This also means the duration of a job is determined by the slowest mapper. - A MR job can only hold its containers for a limited of time, beyond which the job may get killed. Real-time data ingestion, however, requires the ingestion tasks to be running all the time or alternatively dividing a continuous data stream into well-defined mini-batches (as in Spark Streaming) that can be promptly executed once created. Both require long-running containers, which are not supported in the MR mode.
Those deficiencies motivated the work on making Gobblin run on Yarn as a native Yarn application. Running Gobblin as a native Yarn application allows much more control over container provisioning and lifecycle management so it's possible to keep the containers running continuously. It also makes it possible to dynamically change the number of containers at runtime depending on the load to further improve the resource efficiency, something that's impossible in the MR mode.
This wiki page documents the design and architecture of the native Gobblin Yarn application and some implementation details. It also covers the configuration system and properties for the application, as well as deployment settings on both unsecured and secured Yarn clusters.
Architecture
Overview
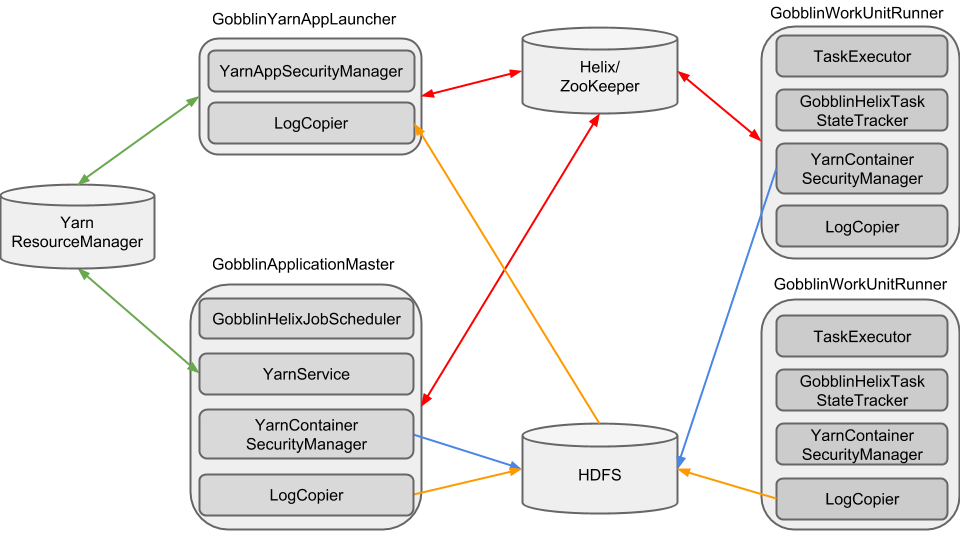
The architecture of Gobblin on Yarn is illustrated in the following diagram. In addition to Yarn, Gobblin on Yarn also leverages Apache Helix, whose role is discussed in The Role of Apache Helix. A Gobblin Yarn application consists of three components: the Yarn Application Launcher, the Yarn ApplicationMaster (serving as the Helix controller), and the Yarn WorkUnitRunner (serving as the Helix participant). The following sections describe each component in details.
The Role of Apache Helix
Apache Helix is mainly used for managing the cluster of containers and running the WorkUnits through its Distributed Task Execution Framework.
The assignment of tasks to available containers (or participants in Helix's term) is handled by Helix through a finite state model named the TaskStateModel. Using this TaskStateModel, Helix is also able to do task rebalancing in case new containers get added or some existing containers die. Clients can also choose to force a task rebalancing if some tasks take much longer time than the others.
Helix also supports a way of doing messaging between different components of a cluster, e.g., between the controller to the participants, or between the client and the controller. The Gobblin Yarn application uses this messaging mechanism to implement graceful shutdown initiated by the client as well as delegation token renew notifications from the client to the ApplicationMaster and the WorkUnitRunner containers.
Heiix relies on ZooKeeper for its operations, and particularly for maintaining the state of the cluster and the resources (tasks in this case). Both the Helix controller and participants connect to ZooKeeper during their entire lifetime. The ApplicationMaster serves as the Helix controller and the worker containers serve as the Helix participants, respectively, as discussed in details below.
Gobblin Yarn Application Launcher
The Gobblin Yarn Application Launcher (implemented by class GobblinYarnAppLauncher) is the client/driver of a Gobblin Yarn application. The first thing the GobblinYarnAppLauncher does when it starts is to register itself with Helix as a spectator and creates a new Helix cluster with name specified through the configuration property gobblin.yarn.helix.cluster.name, if no cluster with the name exists.
The GobblinYarnAppLauncher then sets up the Gobblin Yarn application and submits it to run on Yarn. Once the Yarn application successfully starts running, it starts an application state monitor that periodically checks the state of the Gobblin Yarn application. If the state is one of the exit states (FINISHED, FAILED, or KILLED), the GobblinYarnAppLauncher shuts down itself.
Upon successfully submitting the application to run on Yarn, the GobblinYarnAppLauncher also starts a ServiceManager that manages the following services that auxiliate the running of the application:
YarnAppSecurityManager
The YarnAppSecurityManager works with the YarnContainerSecurityManager running in the ApplicationMaster and the WorkUnitRunner for a complete solution for security and delegation token management. The YarnAppSecurityManager is responsible for periodically logging in through a Kerberos keytab and getting the delegation token refreshed regularly after each login. Each time the delegation token is refreshed, the YarnContainerSecurityManager writes the new token to a file on HDFS and sends a message to the ApplicationMaster and each WorkUnitRunner, notifying them the refresh of the delegation token. Checkout YarnContainerSecurityManager on how the other side of this system works.
LogCopier
The service LogCopier in GobblinYarnAppLauncher streams the ApplicationMaster and WorkUnitRunner logs in near real-time from the central location on HDFS where the logs are streamed to from the ApplicationMaster and WorkUnitRunner containers, to the local directory specified through the configuration property gobblin.yarn.logs.sink.root.dir on the machine where the GobblinYarnAppLauncher runs. More details on this can be found in Log Aggregation.
Gobblin ApplicationMaster
The ApplicationMaster process runs the GobblinApplicationMaster, which uses a ServiceManager to manage the services supporting the operation of the ApplicationMaster process. The services running in GobblinApplicationMaster will be discussed later. When it starts, the first thing GobblinApplicationMaster does is to connect to ZooKeeper and register itself as a Helix controller. It then starts the ServiceManager, which in turn starts the services it manages, as described below.
YarnService
The service YarnService handles all Yarn-related task including the following:
- Registering and un-registering the ApplicationMaster with the Yarn ResourceManager.
- Requesting the initial set of containers from the Yarn ResourceManager.
- Handling any container changes at runtime, e.g., adding more containers or shutting down containers no longer needed. This also includes stopping running containers when the application is asked to stop.
This design makes it switch to a different resource manager, e.g., Mesos, by replacing the service YarnService with something else specific to the resource manager, e.g., MesosService.
GobblinHelixJobScheduler
GobblinApplicationMaster runs the GobblinHelixJobScheduler that schedules jobs to run through the Helix Distributed Task Execution Framework. For each Gobblin job run, the GobblinHelixJobScheduler starts a GobblinHelixJobLauncher that wraps the Gobblin job into a GobblinHelixJob and each Gobblin Task into a GobblinHelixTask, which implements the Helix's Task interface so Helix knows how to execute it. The GobblinHelixJobLauncher then submits the job to a Helix job queue named after the Gobblin job name, from which the Helix Distributed Task Execution Framework picks up the job and runs its tasks through the live participants (available containers).
Like the LocalJobLauncher and MRJobLauncher, the GobblinHelixJobLauncher handles output data commit and job state persistence.
LogCopier
The service LogCopier in GobblinApplicationMaster streams the ApplicationMaster logs in near real-time from the machine running the ApplicationMaster container to a central location on HDFS so the logs can be accessed at runtime. More details on this can be found in Log Aggregation.
YarnContainerSecurityManager
The YarnContainerSecurityManager runs in both the ApplicationMaster and the WorkUnitRunner. When it starts, it registers a message handler with the HelixManager for handling messages on refreshes of the delegation token. Once such a message is received, the YarnContainerSecurityManager gets the path to the token file on HDFS from the message, and updated the the current login user with the new token read from the file.
Gobblin WorkUnitRunner
The WorkUnitRunner process runs as part of GobblinTaskRunner, which uses a ServiceManager to manage the services supporting the operation of the WorkUnitRunner process. The services running in GobblinWorkUnitRunner will be discussed later. When it starts, the first thing GobblinWorkUnitRunner does is to connect to ZooKeeper and register itself as a Helix participant. It then starts the ServiceManager, which in turn starts the services it manages, as discussed below.
TaskExecutor
The TaskExecutor remains the same as in the standalone and MR modes, and is purely responsible for running tasks assigned to a WorkUnitRunner.
GobblinHelixTaskStateTracker
The GobblinHelixTaskStateTracker has a similar responsibility as the LocalTaskStateTracker and MRTaskStateTracker: keeping track of the state of running tasks including operational metrics, e.g., total records pulled, records pulled per second, total bytes pulled, bytes pulled per second, etc.
LogCopier
The service LogCopier in GobblinWorkUnitRunner streams the WorkUnitRunner logs in near real-time from the machine running the WorkUnitRunner container to a central location on HDFS so the logs can be accessed at runtime. More details on this can be found in Log Aggregation.
YarnContainerSecurityManager
The YarnContainerSecurityManager in GobblinWorkUnitRunner works in the same way as it in GobblinApplicationMaster.
Failure Handling
ApplicationMaster Failure Handling
Under normal operation, the Gobblin ApplicationMaster stays alive unless being asked to stop through a message sent from the launcher (the GobblinYarnAppLauncher) as part of the orderly shutdown process. It may, however, fail or get killed by the Yarn ResourceManager for various reasons. For example, the container running the ApplicationMaster may fail and exit due to node failures, or get killed because of using more memory than claimed. When a shutdown of the ApplicationMaster is triggered (e.g., when the shutdown hook is triggered) for any reason, it does so gracefully, i.e., it attempts to stop every services it manages, stop all the running containers, and unregister itself with the ResourceManager. Shutting down the ApplicationMaster shuts down the Yarn application and the application launcher will eventually know that the application completes through a periodic check on the application status.
Container Failure Handling
Under normal operation, a Gobblin Yarn container stays alive unless being released and stopped by the Gobblin ApplicationMaster, and in this case the exit status of the container will be zero. However, a container may exit unexpectedly due to various reasons. For example, a container may fail and exit due to node failures, or be killed because of using more memory than claimed. In this case when a container exits abnormally with a non-zero exit code, Gobblin Yarn tries to restart the Helix instance running in the container by requesting a new Yarn container as a replacement to run the instance. The maximum number of retries can be configured through the key gobblin.yarn.helix.instance.max.retries.
When requesting a new container to replace the one that completes and exits abnormally, the application has a choice of specifying the same host that runs the completed container as the preferred host, depending on the boolean value of configuration key gobblin.yarn.container.affinity.enabled. Note that for certain exit codes that indicate something wrong with the host, the value of gobblin.yarn.container.affinity.enabled is ignored and no preferred host gets specified, leaving Yarn to figure out a good candidate node for the new container.
Handling Failures to get ApplicationReport
As mentioned above, once the Gobblin Yarn application successfully starts running, the GobblinYarnAppLauncher starts an application state monitor that periodically checks the state of the Yarn application by getting an ApplicationReport. It may fail to do so and throw an exception, however, if the Yarn client is having some problem connecting and communicating with the Yarn cluster. For example, if the Yarn cluster is down for maintenance, the Yarn client will not be able to get an ApplicationReport. The GobblinYarnAppLauncher keeps track of the number of consecutive failures to get an ApplicationReport and initiates a shutdown if this number exceeds the threshold as specified through the configuration property gobblin.yarn.max.get.app.report.failures. The shutdown will trigger an email notification if the configuration property gobblin.yarn.email.notification.on.shutdown is set to true.
Log Aggregation
Yarn provides both a Web UI and a command-line tool to access the logs of an application, and also does log aggregation so the logs of all the containers become available on the client side upon requested. However, there are a few limitations that make it hard to access the logs of an application at runtime:
- The command-line utility for downloading the aggregated logs will only be able to do so after the application finishes, making it useless for getting access to the logs at the application runtime.
- The Web UI does allow logs to be viewed at runtime, but only when the user that access the UI is the same as the user that launches the application. On a Yarn cluster where security is enabled, the user launching the Gobblin Yarn application is typically a user of some headless account.
Because Gobblin runs on Yarn as a long-running native Yarn application, getting access to the logs at runtime is critical to know what's going on in the application and to detect any issues in the application as early as possible. Unfortunately we cannot use the log facility provided by Yarn here due to the above limitations. Alternatively, Gobblin on Yarn has its own mechanism for doing log aggregation and providing access to the logs at runtime, described as follows.
Both the Gobblin ApplicationMaster and WorkUnitRunner run a LogCopier that periodically copies new entries of both stdout and stderr logs of the corresponding processes from the containers to a central location on HDFS under the directory ${gobblin.yarn.work.dir}/_applogs in the subdirectories named after the container IDs, one per container. The names of the log files on HDFS combine the container IDs and the original log file names so it's easy to tell which container generates which log file. More specifically, the log files produced by the ApplicationMaster are named <container id>.GobblinApplicationMaster.{stdout,stderr}, and the log files produced by the WorkUnitRunner are named <container id>.GobblinWorkUnitRunner.{stdout,stderr}.
The Gobblin YarnApplicationLauncher also runs a LogCopier that periodically copies new log entries from log files under ${gobblin.yarn.work.dir}/_applogs on HDFS to the local filesystem under the directory configured by the property gobblin.yarn.logs.sink.root.dir. By default, the LogCopier checks for new log entries every 60 seconds and will keep reading new log entries until it reaches the end of the log file. This setup enables the Gobblin Yarn application to stream container process logs near real-time all the way to the client/driver.
Security and Delegation Token Management
On a Yarn cluster with security enabled (e.g., Kerberos authentication is required to access HDFS), security and delegation token management is necessary to allow Gobblin run as a long-running Yarn application. Specifically, Gobblin running on a secured Yarn cluster needs to get its delegation token for accessing HDFS renewed periodically, which also requires periodic keytab re-logins because a delegation token can only be renewed up to a limited number of times in one login.
The Gobblin Yarn application supports Kerberos-based authentication and login through a keytab file. The YarnAppSecurityManager running in the Yarn Application Launcher and the YarnContainerSecurityManager running in the ApplicationMaster and WorkUnitRunner work together to get every Yarn containers updated whenever the delegation token gets updated on the client side by the YarnAppSecurityManager. More specifically, the YarnAppSecurityManager periodically logins through the keytab and gets the delegation token refreshed regularly after each successful login. Every time the YarnAppSecurityManager refreshes the delegation token, the YarnContainerSecurityManager writes the new token to a file on HDFS and sends a TOKEN_FILE_UPDATED message to the ApplicationMaster and each WorkUnitRunner, notifying them the refresh of the delegation token. Upon receiving such a message, the YarnContainerSecurityManager running in the ApplicationMaster or WorkUnitRunner gets the path to the token file on HDFS from the message, and updated the the current login user with the new token read from the file.
Both the interval between two Kerberos keytab logins and the interval between two delegation token refreshes are configurable, through the configuration properties gobblin.yarn.login.interval.minutes and gobblin.yarn.token.renew.interval.minutes, respectively.
Configuration
Configuration Properties
In additional to the common Gobblin configuration properties, documented in Configuration Properties Glossary, Gobblin on Yarn uses the following configuration properties.
| Property | Default Value | Description |
|---|---|---|
gobblin.yarn.app.name |
GobblinYarn |
The Gobblin Yarn appliation name. |
gobblin.yarn.app.queue |
default |
The Yarn queue the Gobblin Yarn application will run in. |
gobblin.yarn.work.dir |
/gobblin |
The working directory (typically on HDFS) for the Gobblin Yarn application. |
gobblin.yarn.app.report.interval.minutes |
5 | The interval in minutes between two Gobblin Yarn application status reports. |
gobblin.yarn.max.get.app.report.failures |
4 | Maximum allowed number of consecutive failures to get a Yarn ApplicationReport. |
gobblin.yarn.email.notification.on.shutdown |
false |
Whether email notification is enabled or not on shutdown of the GobblinYarnAppLauncher. If this is set to true, the following configuration properties also need to be set for email notification to work: email.host, email.smtp.port, email.user, email.password, email.from, and email.tos. Refer to Email Alert Properties for more information on those configuration properties. |
gobblin.yarn.app.master.memory.mbs |
512 | How much memory in MBs to request for the container running the Gobblin ApplicationMaster. |
gobblin.yarn.app.master.cores |
1 | The number of vcores to request for the container running the Gobblin ApplicationMaster. |
gobblin.yarn.app.master.jars |
A comma-separated list of jars the Gobblin ApplicationMaster depends on but not in the lib directory. |
|
gobblin.yarn.app.master.files.local |
A comma-separated list of files on the local filesystem the Gobblin ApplicationMaster depends on. | |
gobblin.yarn.app.master.files.remote |
A comma-separated list of files on a remote filesystem (typically HDFS) the Gobblin ApplicationMaster depends on. | |
gobblin.yarn.app.master.jvm.args |
Additional JVM arguments for the JVM process running the Gobblin ApplicationMaster, e.g., -XX:ReservedCodeCacheSize=100M -XX:MaxMetaspaceSize=256m -XX:CompressedClassSpaceSize=256m -Dconfig.trace=loads. |
|
gobblin.yarn.initial.containers |
1 | The number of containers to request initially when the application starts to run the WorkUnitRunner. |
gobblin.yarn.container.memory.mbs |
512 | How much memory in MBs to request for the container running the Gobblin WorkUnitRunner. |
gobblin.yarn.container.cores |
1 | The number of vcores to request for the container running the Gobblin WorkUnitRunner. |
gobblin.yarn.container.jars |
A comma-separated list of jars the Gobblin WorkUnitRunner depends on but not in the lib directory. |
|
gobblin.yarn.container.files.local |
A comma-separated list of files on the local filesystem the Gobblin WorkUnitRunner depends on. | |
gobblin.yarn.container.files.remote |
A comma-separated list of files on a remote filesystem (typically HDFS) the Gobblin WorkUnitRunner depends on. | |
gobblin.yarn.container.jvm.args |
Additional JVM arguments for the JVM process running the Gobblin WorkUnitRunner, e.g., -XX:ReservedCodeCacheSize=100M -XX:MaxMetaspaceSize=256m -XX:CompressedClassSpaceSize=256m -Dconfig.trace=loads. |
|
gobblin.yarn.container.affinity.enabled |
true |
Whether the same host should be used as the preferred host when requesting a replacement container for the one that exits. |
gobblin.yarn.helix.cluster.name |
GobblinYarn |
The name of the Helix cluster that will be registered with ZooKeeper. |
gobblin.yarn.zk.connection.string |
localhost:2181 |
The ZooKeeper connection string used by Helix. |
helix.instance.max.retries |
2 | Maximum number of times the application tries to restart a failed Helix instance (corresponding to a Yarn container). |
gobblin.yarn.lib.jars.dir |
The directory where library jars are stored, typically gobblin-dist/lib. |
|
gobblin.yarn.job.conf.path |
The path to either a directory where Gobblin job configuration files are stored or a single job configuration file. Internally Gobblin Yarn will package the configuration files as a tarball so you don't need to. | |
gobblin.yarn.logs.sink.root.dir |
The directory on local filesystem on the driver/client side where the aggregated container logs of both the ApplicationMaster and WorkUnitRunner are stored. | |
gobblin.yarn.log.copier.max.file.size |
Unbounded | The maximum bytes per log file. When this is exceeded a new log file will be created. |
gobblin.yarn.log.copier.scheduler |
ScheduledExecutorService |
The scheduler to use to copy the log files. Possible values: ScheduledExecutorService, HashedWheelTimer. The HashedWheelTimer scheduler is experimental but is expected to become the default after a sufficient burn in period. |
gobblin.yarn.keytab.file.path |
The path to the Kerberos keytab file used for keytab-based authentication/login. | |
gobblin.yarn.keytab.principal.name |
The principal name of the keytab. | |
gobblin.yarn.login.interval.minutes |
1440 | The interval in minutes between two keytab logins. |
gobblin.yarn.token.renew.interval.minutes |
720 | The interval in minutes between two delegation token renews. |
Job Lock
It is recommended to use zookeeper for maintaining job locks. See ZookeeperBasedJobLock Properties for the relevant configuration properties.
Configuration System
The Gobblin Yarn application uses the Typesafe Config library to handle the application configuration. Following Typesafe Config's model, the Gobblin Yarn application uses a single file named application.conf for all configuration properties and another file named reference.conf for default values. A sample application.conf is shown below:
# Yarn/Helix configuration properties
gobblin.yarn.helix.cluster.name=GobblinYarnTest
gobblin.yarn.app.name=GobblinYarnTest
gobblin.yarn.lib.jars.dir="/home/gobblin/gobblin-dist/lib/"
gobblin.yarn.app.master.files.local="/home/gobblin/gobblin-dist/conf/log4j-yarn.properties,/home/gobblin/gobblin-dist/conf/application.conf,/home/gobblin/gobblin-dist/conf/reference.conf"
gobblin.yarn.container.files.local=${gobblin.yarn.app.master.files.local}
gobblin.yarn.job.conf.path="/home/gobblin/gobblin-dist/job-conf"
gobblin.yarn.keytab.file.path="/home/gobblin/gobblin.headless.keytab"
gobblin.yarn.keytab.principal.name=gobblin
gobblin.yarn.app.master.jvm.args="-XX:ReservedCodeCacheSize=100M -XX:MaxMetaspaceSize=256m -XX:CompressedClassSpaceSize=256m"
gobblin.yarn.container.jvm.args="-XX:ReservedCodeCacheSize=100M -XX:MaxMetaspaceSize=256m -XX:CompressedClassSpaceSize=256m"
gobblin.yarn.logs.sink.root.dir=/home/gobblin/gobblin-dist/applogs
# File system URIs
writer.fs.uri=${fs.uri}
state.store.fs.uri=${fs.uri}
# Writer related configuration properties
writer.destination.type=HDFS
writer.output.format=AVRO
writer.staging.dir=${gobblin.yarn.work.dir}/task-staging
writer.output.dir=${gobblin.yarn.work.dir}/task-output
# Data publisher related configuration properties
data.publisher.type=org.apache.gobblin.publisher.BaseDataPublisher
data.publisher.final.dir=${gobblin.yarn.work.dir}/job-output
data.publisher.replace.final.dir=false
# Directory where job/task state files are stored
state.store.dir=${gobblin.yarn.work.dir}/state-store
# Directory where error files from the quality checkers are stored
qualitychecker.row.err.file=${gobblin.yarn.work.dir}/err
# Use zookeeper for maintaining the job lock
job.lock.enabled=true
job.lock.type=ZookeeperBasedJobLock
# Directory where job locks are stored
job.lock.dir=${gobblin.yarn.work.dir}/locks
# Directory where metrics log files are stored
metrics.log.dir=${gobblin.yarn.work.dir}/metrics
A sample reference.conf is shown below:
# Yarn/Helix configuration properties
gobblin.yarn.app.queue=default
gobblin.yarn.helix.cluster.name=GobblinYarn
gobblin.yarn.app.name=GobblinYarn
gobblin.yarn.app.master.memory.mbs=512
gobblin.yarn.app.master.cores=1
gobblin.yarn.app.report.interval.minutes=5
gobblin.yarn.max.get.app.report.failures=4
gobblin.yarn.email.notification.on.shutdown=false
gobblin.yarn.initial.containers=1
gobblin.yarn.container.memory.mbs=512
gobblin.yarn.container.cores=1
gobblin.yarn.container.affinity.enabled=true
gobblin.yarn.helix.instance.max.retries=2
gobblin.yarn.keytab.login.interval.minutes=1440
gobblin.yarn.token.renew.interval.minutes=720
gobblin.yarn.work.dir=/user/gobblin/gobblin-yarn
gobblin.yarn.zk.connection.string=${zookeeper.connection.string}
fs.uri="hdfs://localhost:9000"
zookeeper.connection.string="localhost:2181"
Deployment
A standard deployment of Gobblin on Yarn requires a Yarn cluster running Hadoop 2.x (2.3.0 and above recommended) and a ZooKeeper cluster. Make sure the client machine (typically the gateway of the Yarn cluster) is able to access the ZooKeeper instance.
Deployment on a Unsecured Yarn Cluster
To do a deployment of the Gobblin Yarn application, first build Gobblin using the following command from the root directory of the Gobblin project.
./gradlew clean build
To build Gobblin against a specific version of Hadoop 2.x, e.g., 2.7.0, run the following command instead:
./gradlew clean build -PhadoopVersion=2.7.0
After Gobblin is successfully built, a tarball named gobblin-dist-[project-version].tar.gz should have been created under the root directory of the project. To deploy the Gobblin Yarn application on a unsecured Yarn cluster, uncompress the tarball somewhere and run the following commands:
cd gobblin-dist
bin/gobblin-yarn.sh
Note that for the above commands to work, the Hadoop/Yarn configuration directory must be on the classpath and the configuration must be pointing to the right Yarn cluster, or specifically the right ResourceManager and NameNode URLs. This is defined like the following in gobblin-yarn.sh:
CLASSPATH=${FWDIR_CONF}:${GOBBLIN_JARS}:${YARN_CONF_DIR}:${HADOOP_YARN_HOME}/lib
Deployment on a Secured Yarn Cluster
When deploying the Gobblin Yarn application on a secured Yarn cluster, make sure the keytab file path is correctly specified in application.conf and the correct principal for the keytab is used as follows. The rest of the deployment is the same as that on a unsecured Yarn cluster.
gobblin.yarn.keytab.file.path="/home/gobblin/gobblin.headless.keytab"
gobblin.yarn.keytab.principal.name=gobblin
Supporting Existing Gobblin Jobs
Gobblin on Yarn is backward compatible and supports existing Gobblin jobs running in the standalone and MR modes. To run existing Gobblin jobs, simply put the job configuration files into a directory on the local file system of the driver and setting the configuration property gobblin.yarn.job.conf.path to point to the directory. When the Gobblin Yarn application starts, Yarn will package the configuration files as a tarball and make sure the tarball gets copied to the ApplicationMaster and properly uncompressed. The GobblinHelixJobScheduler then loads the job configuration files and schedule the jobs to run.
Monitoring
Gobblin Yarn uses the Gobblin Metrics library for collecting and reporting metrics at the container, job, and task levels. Each GobblinWorkUnitRunner maintains a ContainerMetrics that is the parent of the JobMetrics of each job run the container is involved, which is the parent of the TaskMetrics of each task of the job run. This hierarchical structure allows us to do pre-aggregation in the containers before reporting the metrics to the backend.
Collected metrics can be reported to various sinks such as Kafka, files, and JMX, depending on the configuration. Specifically, metrics.enabled controls whether metrics collecting and reporting are enabled or not. metrics.reporting.kafka.enabled, metrics.reporting.file.enabled, and metrics.reporting.jmx.enabled control whether collected metrics should be reported or not to Kafka, files, and JMX, respectively. Please refer to Metrics Properties for the available configuration properties related to metrics collecting and reporting.
In addition to metric collecting and reporting, Gobblin Yarn also supports writing job execution information to a MySQL-backed job execution history store, which keeps track of job execution information. Please refer to the DDL for the relevant MySQL tables. Detailed information on the job execution history store including how to configure it can be found here.